
一文了解“字符集”!
- 在计算机中每个字符都要使用一个编码来表示,而每个字符究竟使用哪个编码来表示要取决于使用哪个字符集(Charset)。
- 计算机字符集可归类为3种:单字节字符集(SBCS)、多字节字符集(MBCS)和宽字符集(Unicode字符集)。
1 单字节字符集(SBCS)
- 单字节字符集的所有字符都只有一个字节的长度。单字节字符集(SBCS)是一个理论指导导规范。具体实现时有两种字符集:ASCII字符集和扩展ASCII字符集。
- ASCII字符集主要用于美国,是由美国国家标准局(ANSI)顺布的,全称是美国国家标准信息交换码(
American National Standard Code For Information Interchange),使用7位(bit)来表示一个字符,总共可以表示128个字符(0一127),不过一个字节有8位,有1位没有用到,因此人们把最高1位永远设为0,用剩下的7位组成的编码来表示字符集的128个字符。ASCII字符集包括英文字母、数字、标点符号等常用字符,如字符'A'的ASCII码是65、字符'a'的ASCII码是97、字符'0'的ASCII码是48、字符'1'的ASCII码是49。其他字符编码的具体细节可以查看ASCII码表。
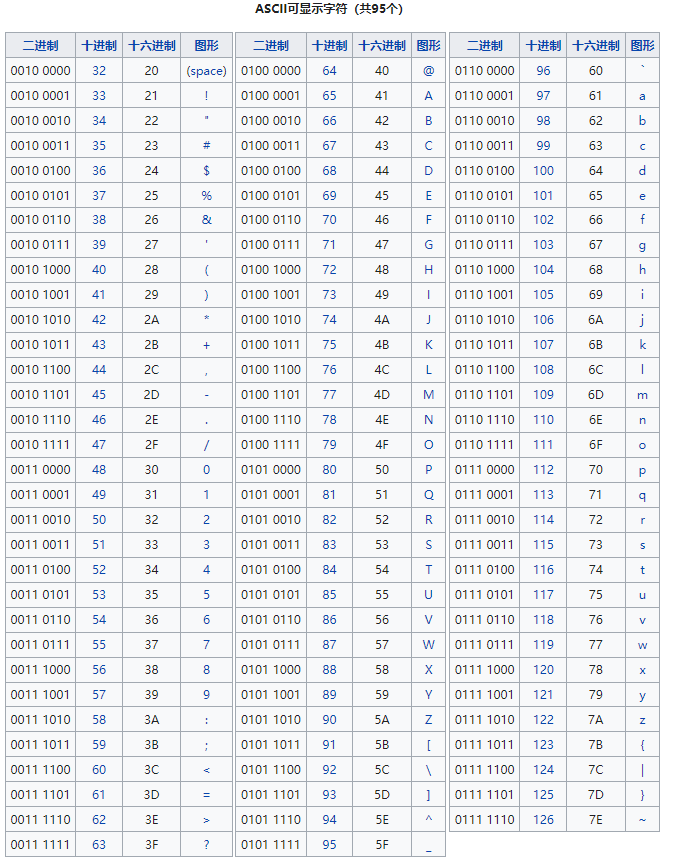
- 在美国刚刚兴起计算机的时候,ASCII字符集中的128个字符就够用了,一切应用都是顺顺当当的。后来计算机发展到欧洲,欧洲各个国家的字符较多,128个就不够用了,怎么办?人们对ASCII码进行了扩展,因此就有了扩展ASCII字符集。它使用8位来表示一个字符,即可表示256个字符,在前面0到127的编码范围内定义的字符与ASCII字符集中的字符相同,后面多出来的128个字符用来表示欧洲国家的一些字符,如拉丁字母、希腊字母等。有了扩展的ASCII字符集,计算机在欧洲的发展也就顺风顺水了。
2 多字节字符集(MBCS)
- 随着计算机普及到更多国家和地区(比如东亚和中东),需要的字符就更多了,8位的单字节字符集不能满足信息这些国家和地区交流的需要。因此,为了能够表示更多国家和地区的文字(比如中文),人们对ASCII码继续扩展,也就是在欧洲人扩展的基础上再进行扩展,即英文字母和欧洲字符为了和扩展ASCII兼容,依然用1个字节表示字符,而对于更多国家和地区自己的字符(如中文字符)则用2个字节来表示,这就是多字节字符集(Muli-Byte Character System,MBCS),它也是一个理论指导规范,具体实现时各个国家或地区根据自己的语言字符分别实现了不同的字符集,比如中国大陆实现了GB-2312字符集(后来又扩展出GBK和GB18030)、中国台湾地区实现了Big5字符集,日本实现了jis字符集。这些具体的字符集虽然不同,但实现的依据都是MBCS,也就是字符编码256后面的字符都用2个字节来表示。
- MBCS解决了欧美地区以外不同语言中字符的表示,但缺点也很明显。MBCS在保留原有扩展ASCII码(前面256个)的同时,用2个字节来表示其他语言中的字符,这样会导致一个字节和两个字节混在一起,使用起来不太方便。例如,字符串“你好abc”,字符数是5,而字节数是8(因为最后还有一个'\0')。对于用++或--运算符来遍历字符串的程序员来说,这简直就是噩梦。另外,各个国家或地区各自定义的字符集难免会有交集,比如使用简体中文的软件就不能在日文环境下运行(会显示出乱码)。
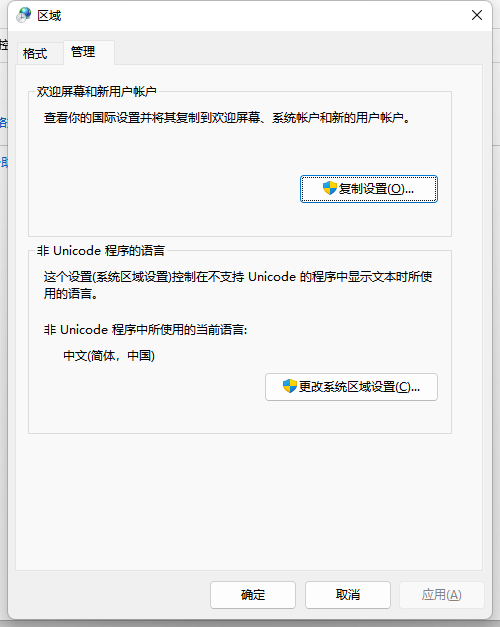
- 这么多国家或地区都定义了各自的多字节字符集,并以此来为自己的文字编码,那么操作系统如何区分这些字符集呢?操作系统通过代码页(Code Page)来为各个字符集定义一个编号,比如437(美国英语)、936(简体中文)、950(繁体中文)、932(日文)、949(朝鲜语朝鲜)、1361(朝鲜语韩国)等都是属于代码页。在Windows操作系统的控制面板中可以设置当前系统所使用的字符集。例如,通过控制面板打开Windows7的“区域和语言”对话框,然后切换到“管理”选项卡,可以看到当前非Unicode(也就是多字节字符集)程序使用的字符集,如下图所示(在Windows10/Windows11中的设置界面与此类似)。我们可以编写一个控制台程序验证一下。注意控制台程序输出窗口默认使用的字符集就是操作系统的代码页,也可以调用Windows API函数SetConsoleOutputCP()修改控制台窗口的代码页。
3 Unicode字符集
3.1 编码方式
- Unicode编码被称为统一码、万国码或单一码。为了把全世界所有的文字符号都统一进行编码,标准化组织IS0提出了Unicode编码方案,这个编码方案可以容纳世界上所有文字和符号的字符编码,并规定任何语言中的任一子符都只对应一个唯一的数字,这个数字被称为代码点(Code Point,或称为码点、码位,用十六进制书写,并加上U+前缀,比如田的代码点是U+7530、'A'的代码点是U+0041。
- 所有字符及其Unicode编码构成的集合叫Unicode字符集(Unicode Characer Set,UCS)。具期的版本有UCS-2,用两个字声进行编码,最多能表示6535个字符。在这个版本中,每个代码点的长度有16位(比特位),用0至65535之间的数字来表示世界上的字符(当初以为够用了),其中0至127这128个数字表示的字符依旧与ASCI码中的字符完全一样,比如Unicode和ASCII中的数字65都表示字母'A'、数字97都表示字母'a'。反过来却是不同的,字符'A'在Unicode中的编码是0xO041、在ASCII中的编码是0x41,虽然它们的值都是97,但是编码的长度是不一样的(Unicode码是16位长度,ASCII码是8位长度)。
- UCS-2后来不够用了,又推出UCS-4版本。UCS-4用4个字节编码(实际上只用了31位,最高位必须为0),它根据最高字节分成2^7=128个组(最高字节的最高位恒为0,所以有128个组)。每个组再根据次高字节分为256个平面(Plane)。每个平面根据第3个字节分为256行(Row),每行有256个码位(Cell)。组0的平面0被称作基本多语言平面(Basic Multilingual Plane, BMP),即范围在UH+00000000到UH+0000FFFF的代码点,若将UCS-4 BMP前面的两个零字节去掉则可得到UCS-2(U+0000~U+FFFF)。每个平面有2^{16}=65536个码位。Unicode计划使用了17个平面,一共有17×65536=1114112个码位。在Unicode5.0.0版本中,已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中,平面15和平面16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000~0xFFFFD和0x100000~Ox10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。平面0也有一个专用区:0xE000~0xF8FF,有6400个码位。平面0的0xD800~0xDFFF共有2048个码位,是一个被称作代理区(Surrogate)的特殊区域。代理区的目的是用两个UTF-16字符表示BMP以外的字符。
- 在Unicode5.0.0版本中,238605-65534×2-6400-2408=99089,余下的99089个已定义码位分布在平面0、平面1、平面2和平面14上,对应Unicode目前定义的99089个字符,其中包括71226个汉字。平面0、平面1、平面2和平面14上分别定义了52080、3419、43253和337个字符。平面2的43253个字符都是汉字。平面0上定义了27973个汉字。

图片来源:维基百科
3.2 实现方式
- Unicode的实现方式不同于编码方式。一个字符的Unicode编码确定。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
- 例如,如果一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。对于这种情况,可以使用UTF-8编码,这是变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1识别。这样对以7位ASCII字符为主的西文文档就大幅节省了编码长度(具体方案参见UTF-8)。类似的,对未来会出现的需要4个字节的辅助平面字符和其他UCS-4扩充字符,2字节编码的UTF-16也需要通过一定的算法转换。
- 再如,如果直接使用与Unicode编码一致(仅限于BMP字符)的UTF-16编码,由于每个字符占用了两个字节,在麦金塔电脑(Mac)机和个人电脑上,对字节顺序的理解不一致。这时同一字节流可能会解释为不同内容,如某字符为十六进制编码4E59,按两个字节拆分为4E和59,在Mac上读取时是从低字节开始,那么在Mac OS会认为此4E59编码为594E,找到的字符为“奎”,而在Windows上从高字节开始读取,则编码为U+4E59的字符为“乙”。就是说在Windows下以UTF-16编码保存一个字符“乙”,在Mac OS环境下开启会显示成“奎”。此类情况说明UTF-16的编码顺序若不加以人为定义就可能发生混淆,于是在UTF-16编码实现方式中使用了大端序(Big-Endian,简写为UTF-16 BE)、小端序(Little-Endian,简写为UTF-16 LE)的概念,以及可附加的字节顺序记号解决方案,目前在个人电脑上的Windows系统和Linux系统对于UTF-16编码默认使用UTF-16 LE。(具体方案参见UTF-16)
- 此外Unicode的实现方式还包括UTF-7、Punycode、CESU-8、SCSU、UTF-32、GB18030等,这些实现方式有些仅在一定的国家和地区使用,有些则属于未来的规划方式。目前通用的实现方式是UTF-16小端序(LE)、UTF-16大端序(BE)和UTF-8。在微软公司Windows XP附带的记事本(Notepad)中,“另存为”对话框可以选择的四种编码方式除去非Unicode编码的ANSI(对于英文系统即ASCII编码,中文系统则为GB2312或Big5编码)外,其余三种为“Unicode”(对应UTF-16 LE)、“Unicode big endian”(对应UTF-16 BE)和“UTF-8”。
- 目前辅助平面的工作主要集中在第二和第三平面的中日韩统一表意文字,因此包括GBK、GB18030、Big5等简体中文、繁体中文、日文、韩文以及越南喃字的各种编码与Unicode的协调性受重点关注。考虑到Unicode最终要涵盖所有的字符。从某种意义而言,这些编码方式也可视作Unicode的出现于其之前的既成事实的实现方式,如同ASCII及其扩展Latin-1一样,后两者的字符在16位Unicode编码空间中的编码第一字节各位全为0,第二字节编码与原编码完全一致。但上述东亚语言编码与Unicode编码的对应关系要复杂得多。
3.3 再归纳总结一下
- 在Unicode字符集中的某个字符对应的代码值称作代码点(Code Point),简称码点,用十六进制书写,并加上U+前缀。
- 后来字符越来越多,最初定义的16位(UCS-2版本)已经不够用,就用32位(UCS-4版本)表示某个字符的代码点,并且把所有代码点分成17个代码平面(Code Plane):其中,U+0000~U+FFFF划入基本多语言平面(Basic Multilingual Plane,BMP);其余划入16个辅助平面(Supplementary Plane),代码点范围为U+10000~U+1OFFFF。
- 并不是每个平面中的代码点都对应有字符,有些是保留的,有些是有特殊用途的。
参考资料:
- 《Qt 5.12实战 朱晨冰 李建英著》3.7 Qt和字符集
- https://zh.wikipedia.org/wiki/Unicode

有任何问题,请联系邮箱:support@progdomain.com
THE END
1
二维码
打赏
海报

一文了解“字符集”!
在计算机中每个字符都要使用一个编码来表示,而每个字符究竟使用哪个编码来表示要取决于使用哪个字符集(Charset)。
计算机字符集可归类为3种:单字节字符集(……


 不会编程的王师兄
不会编程的王师兄

共有 0 条评论